
🌟加入会员后,本站所有内容免费下载,且永久使用!🎉 在个人中心每日签到可白嫖会员!🎁 成为合伙人,免费获取永久会员!
GPT-SoVITS-WebUI一键整合包及使用教程(V2版本)

截至2024年8月30日,GPT-SoVITS-WebUI以及更新到V2版本啦,我们来看下更新了哪些内容:
- SoVITS 增强:对于低音质参考音频,特别是在网络音频中常见的高频缺失和沉闷的听感,V2模型展现出了卓越的音频合成能力。它能够有效提升音频质量,合成出更加清晰、丰富的音频效果。通过先进的处理技术,V2模型能够补充缺失的高频,改善整体音质,提供更为愉悦的听觉体验。这一优势使得V2模型在音频处理领域尤为重要,尤其适用于那些希望提升音频质量的用户。
- 训练集扩充: 经过将训练集扩充至5000小时,V2模型在零样本(zero-shot)性能方面表现得更加出色,合成的音色也更加接近目标音色。这种大规模的训练集不仅丰富了模型的学习数据,还显著提升了其在未见过样本上的适应能力,使得合成音频的质量和真实感得到进一步提升。借助这一进步,用户可以获得更为精确和自然的音色合成效果,推动了音频处理技术的发展。
- 新增语种支持: 最新版本的V2模型新增了对韩语和粤语的支持,现已实现五种语言之间的跨语种合成。这意味着用户可以在训练集、参考音频语种和目标合成语种之间进行互不相同的组合,从而极大地拓展了音频合成的灵活性与应用范围。跨语种合成的能力不仅提升了模型的多样性,还使得不同语言用户能够更方便地实现音频合成,满足了更广泛的需求。
- 文本前端优化:在持续迭代更新的过程中,V2版本中对中文和英文文本的前端进行了多音字优化。这一改进旨在提升文本到语音合成的准确性和自然性,使得合成的语音在表达多音字时更加灵活和贴近真实语言的使用习惯。通过这一优化,用户能够获得更为流畅和清晰的语音输出,进一步增强了音频合成的整体体验。
V1 与 V2 模型对比:
| 特性 | V1 | V2 |
|---|---|---|
| 语种支持(可互相跨语种合成) | 中文、日语、英语 | 中文、日语、英语、韩语、粤语 |
| GPT 训练集时长 | 2k 小时 | 2.5k 小时 |
| SoVITS 训练集时长 | 2k 小时 | VQ 编码器:2k 小时,其他参数:5k 小时 |
| 推理速度 | 基线 | 提升一倍 |
| 参数量 | 200M | 保持不变 |
| 文本前端 | 基线 | 中文、日语、英语逻辑均有增强 |
| 功能 | 基线 | 新增语速调节、无参考文本模式、更优的混合语种切分 |
在人工智能的推动下,语音技术正以前所未有的速度发展,而GPT-SoVITS-WebUI则是这一变革的先锋。该工具能够利用少量的声音源,快速训练出一个高效的语音合成模型(Text-to-Speech,简称TTS)。这一创新不仅提高了语音合成的效率,还使得用户能够以更低的成本和更短的时间,实现高质量的语音生成。
这个强大的Web界面工具不仅提供了零次学习和少量次学习的文本到语音(TTS)功能,还支持跨语种的语音转换,极大地丰富了用户的体验。通过这些功能,它为语音技术的爱好者和开发者打开了一扇新的大门,让他们能够更加灵活地进行语音合成和转换。这一创新使得不同语言之间的语音处理变得更加容易和高效,促进了语音技术在各个领域的应用和发展。
功能亮点
- 零次TTS:只需输入一段5秒的语音样本,GPT-SoVITS-WebUI便能迅速将其转换为文本,用户可以体验到即时的语音到文本转换。这一功能不仅提高了工作效率,还使得语音数据的处理变得更加便捷。
- 少次TTS:通过对模型进行微调,用户仅需提供1分钟的训练数据,即可显著提升语音的相似度和真实感。这一特性对于个性化语音合成尤为关键,因为它能够使合成的语音更贴近用户的需求和偏好。短时间内的有效训练,赋予了语音合成更高的灵活性与准确性,为用户提供了更加个性化和自然的语音体验。
- 跨语言支持: GPT-SoVITS-WebUI具备处理与训练数据集不同语言的语音的能力,目前支持英语、日语和中文。这一功能显著拓宽了其应用范围,使得用户能够在多语言环境中灵活运用语音合成技术。
- WebUI工具集成:该工具集成了多种实用功能,如语音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注。这些功能对于初学者尤其友好,使他们能够轻松创建训练数据集和GPT/SoVITS模型。通过这些便捷的工具,用户可以更高效地处理语音数据,降低学习门槛,快速上手,实现自己的语音合成项目。
快速上手指南
AI工具已经被打包成一键启动的版本,只需轻轻点击即可使用,无需再为环境配置中的各种问题烦恼,一切变得更加便捷高效。
电脑配置要求
- Windows 10/11 64 位操作系统
- 8G显存以上英伟达显卡
- CUDA >= 12.1
- 如果电脑配置不满足要求的话,点我使用4090最强性能运行!
下载和使用教程
1.下载压缩包
下载链接:在右边侧边栏👉
2.解压文件:

3.浏览器访问:
使用教程
获取数据集
1.声音提取:
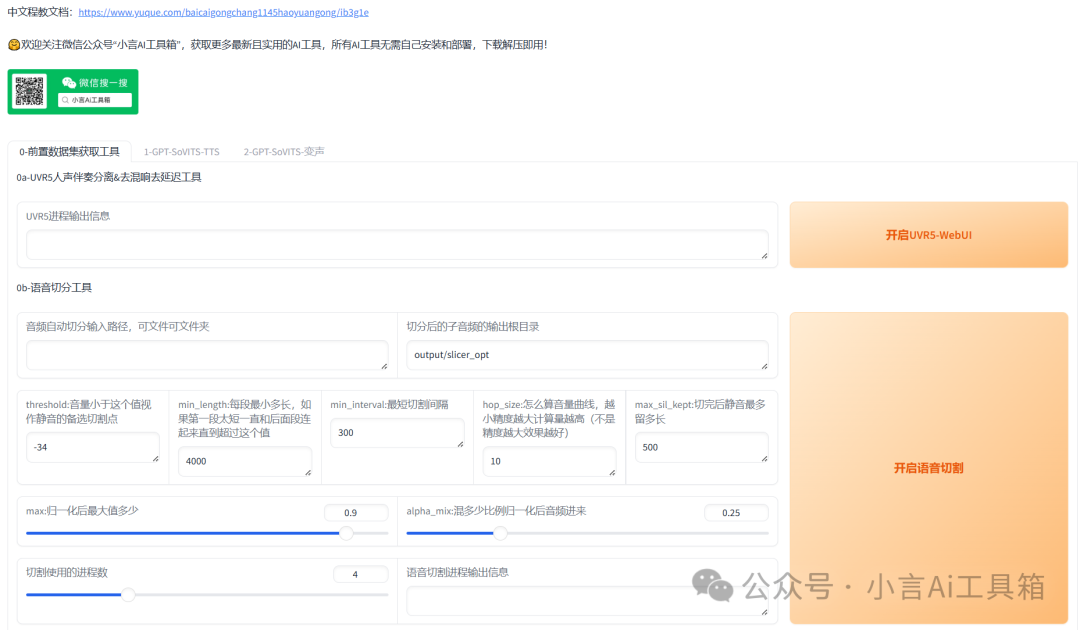
在使用“0a-UVR5人声伴奏分离&去混响去延迟工具”时,我们首先需要选择对应的页面。接着,点击“开启UVR5-WebUI”选项,以便进行声音的提取和制作干声。

稍等一下,会打开一个新的UVR5的WebUI界面。
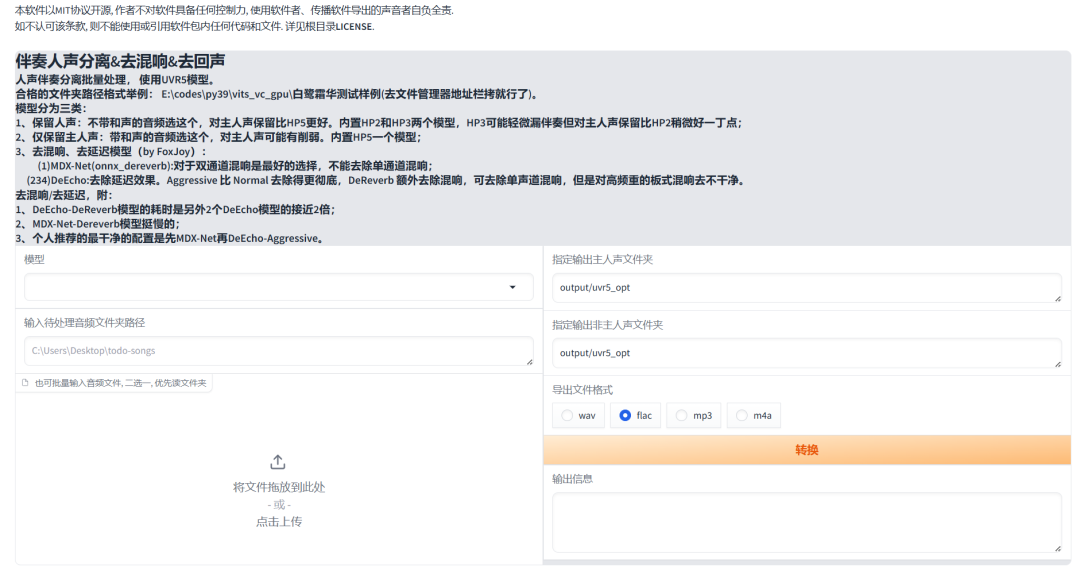
在该界面中,我们将进行干声提取操作。请将准备好的音频或视频文件拖放至界面左下角的输入框中,以便开始处理。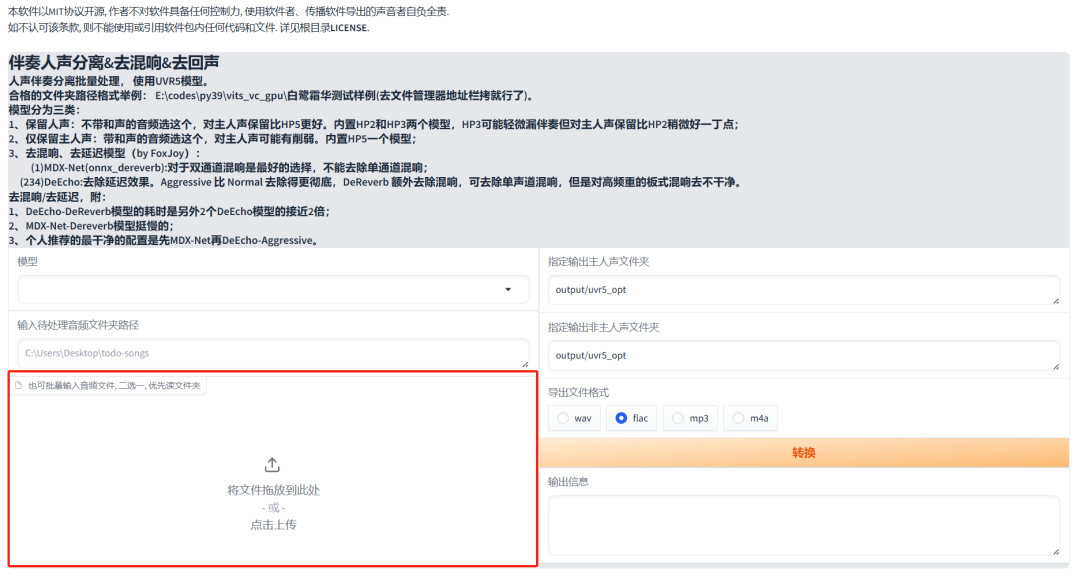
接下来,选择合适的处理模型。如果视频中的声音较为干净,建议选择HP2模型;如果背景噪音较为嘈杂,则应选择HP3模型进行处理。
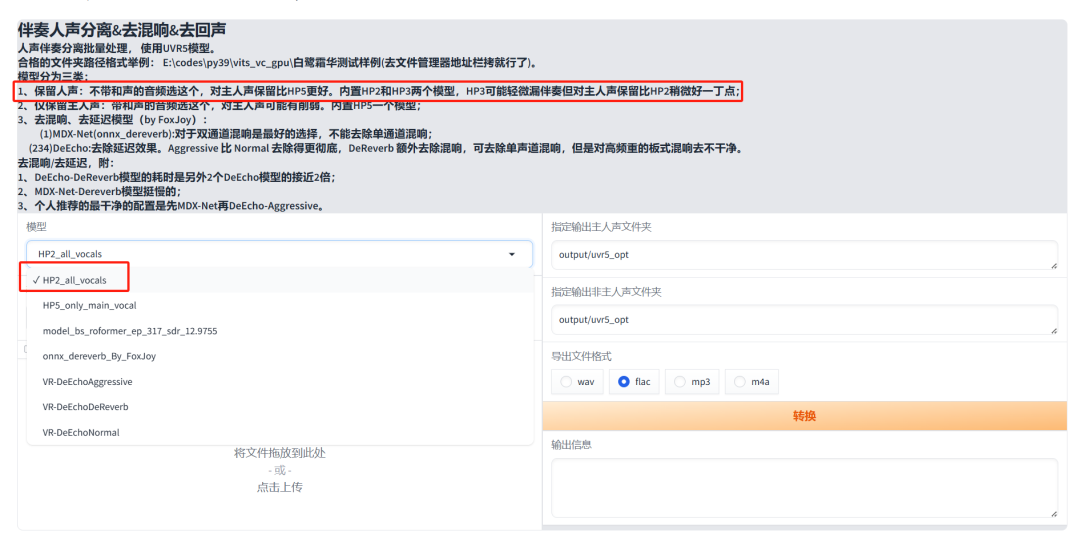
选择好导出文件格式,然后点击 “转换”。
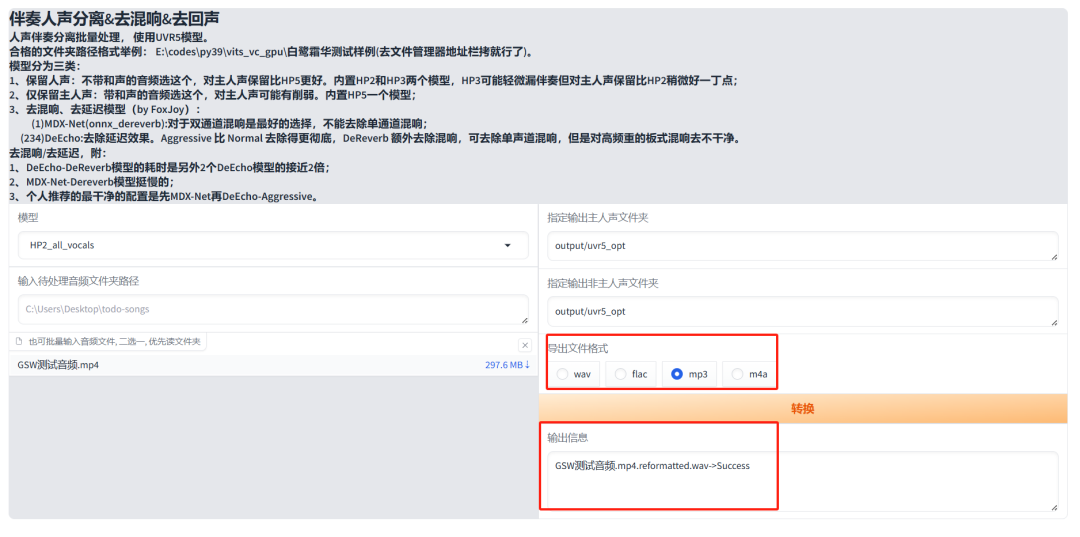
转换成功后,您可以在整合包的 output 路径下的 uvr5 输出目录中找到转换后的结果。
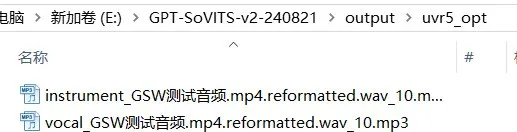
2.语音切分:
关闭 “UVR5-WebUI”,以释放显存。

删除音频分离路径下的背景声音文件后,请将该路径复制到下方的输入框中,以便继续处理。
选择 “0b-语音切分工具” 页签。
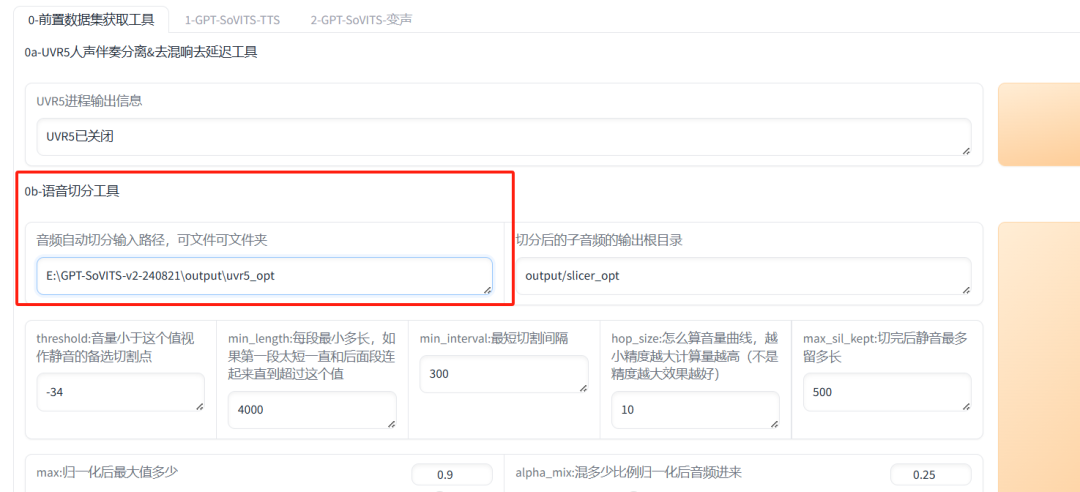
点击 “开始语音切割”。
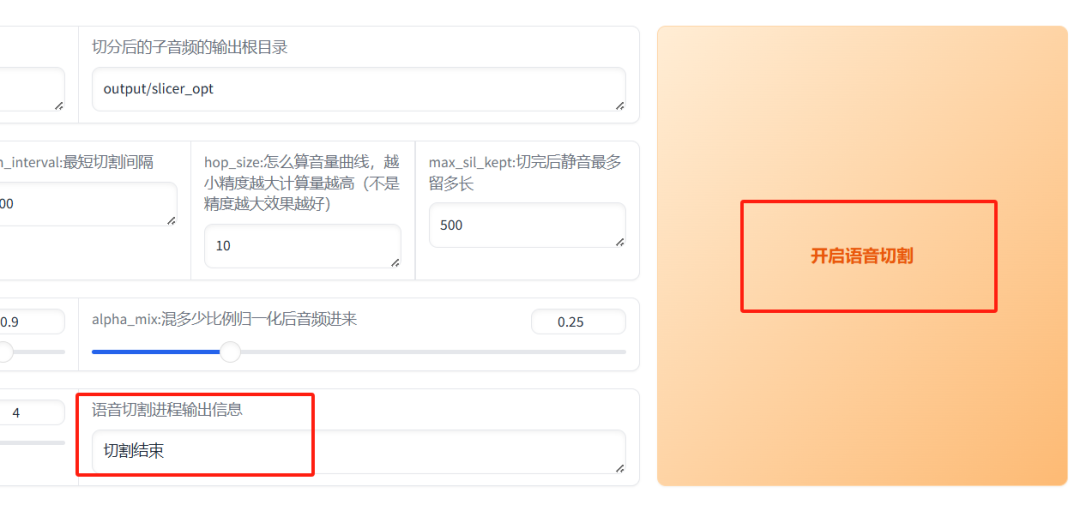
操作完成后,您可以在 \output\slicer_opt 路径下查看切割后的所有音频文件。

3.语音识别:
接下来,选择 “0c-中文批量离线ASR工具” 页签,并将刚刚的分类目录路径复制到下方的 ASR 输入框中,并点击“开启离线批量ASR”。
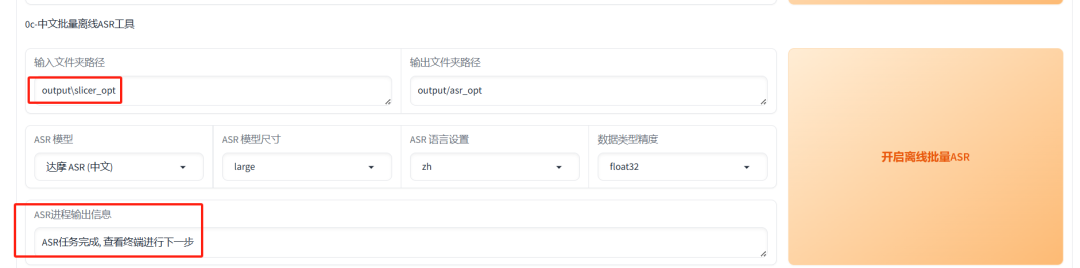
完成后,识别结果会保存在\output\asr_opt目录下。
系统会提示打标工具已成功开启。请稍等片刻,随后会弹出一个新的 WebUI 窗口,这就是标注工具的 WebUI 界面,您可以在此进行进一步的操作。

在这个界面中,您可以进行文本校对,确保标点符号与语音中的停顿相一致。如果某段音频听不清楚、有杂音或语速不稳定,建议删除该段音频,或者返回上一步对音源进行调整。
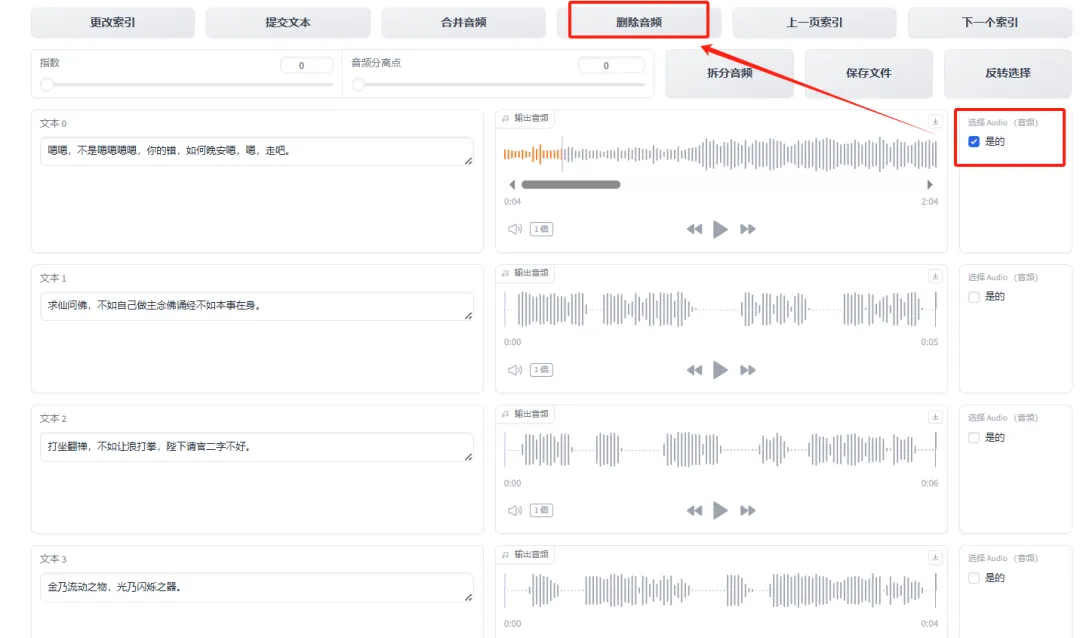
要删除文本,首先勾选需要删除的内容,然后点击“删除”按钮。确保点击“上一页”和“下一页”查看全部内容,避免遗漏。校对无误后,点击保存并提交文本。
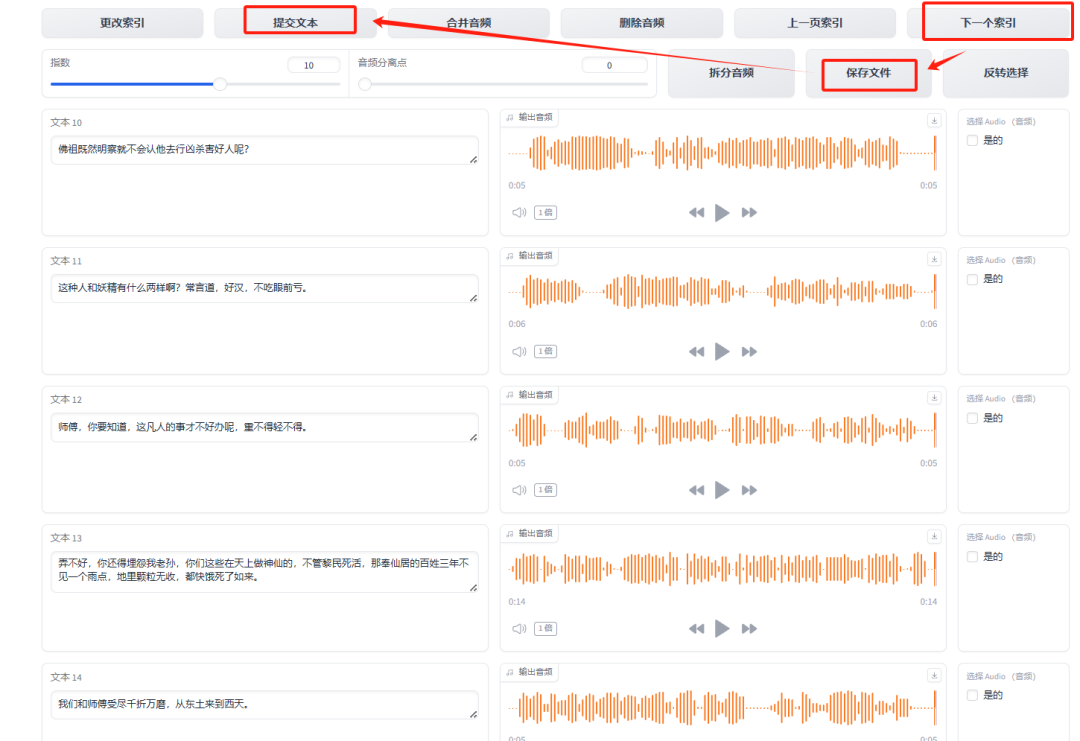
数据将会保存到 **slicer_opt.list** 文件中。至此,前置数据集获取工作已顺利完成。
训练模型
1.训练集格式化:
点击“1A-训练集格式化工具”,进入训练集格式化界面。在此填写训练模型的名称,并输入之前获取的数据集的 list 目录和音频切分目录,准备进行格式化处理。
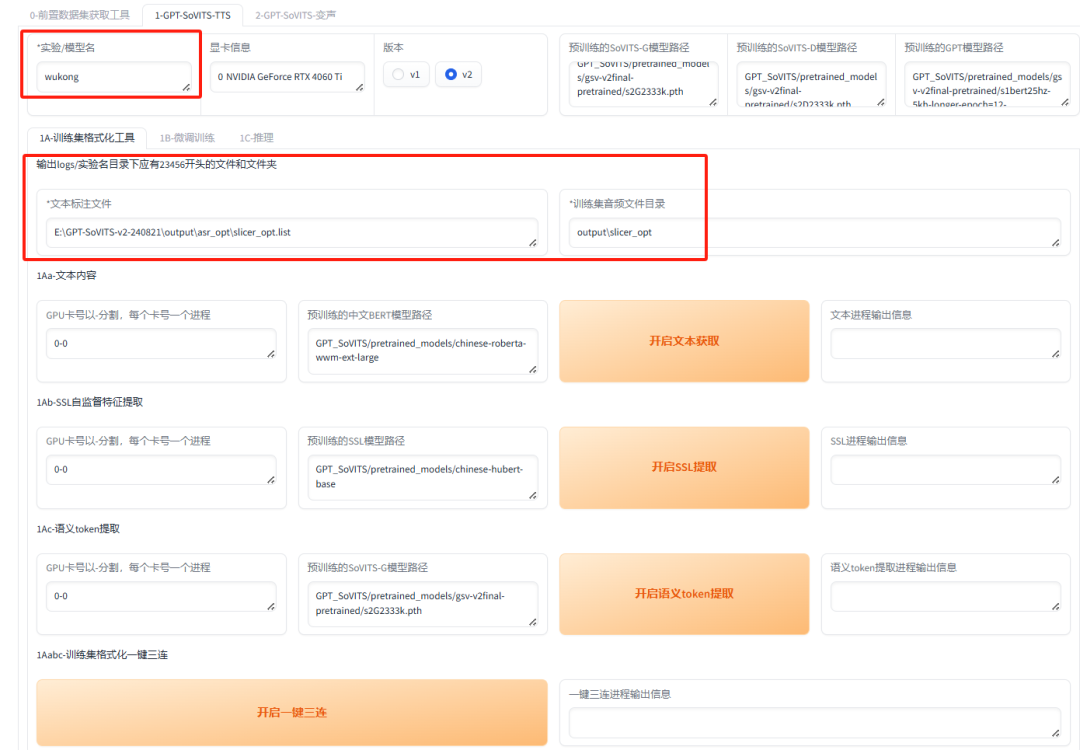
点击下面按钮 “开启一键三连”。

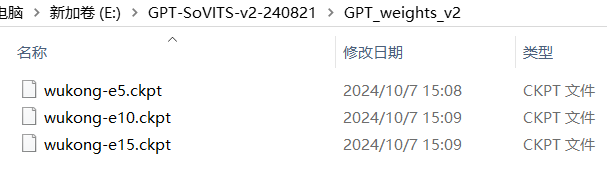
结束后,我们会在\logs\wukong文件下看见23456几个文件。
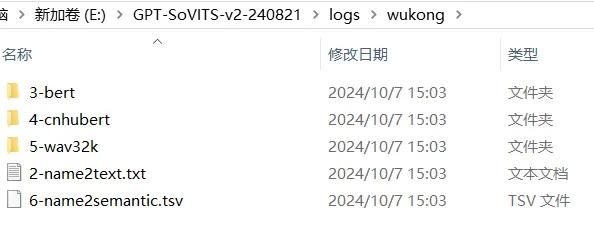
在此步骤中,我们成功生成了后续训练所需的特征缓存文件,为模型训练做好了准备。
2.微调训练:
点击 “1B-微调训练” 页签,进入子模型训练界面。
接下来,我们需要启动两个微调子模型的训练,使用默认参数即可。推荐使用20系列及以上的NVIDIA显卡,显存要求至少8GB。如果显存不足,可以适当降低 **batch_size** 的数值以节省显存资源。
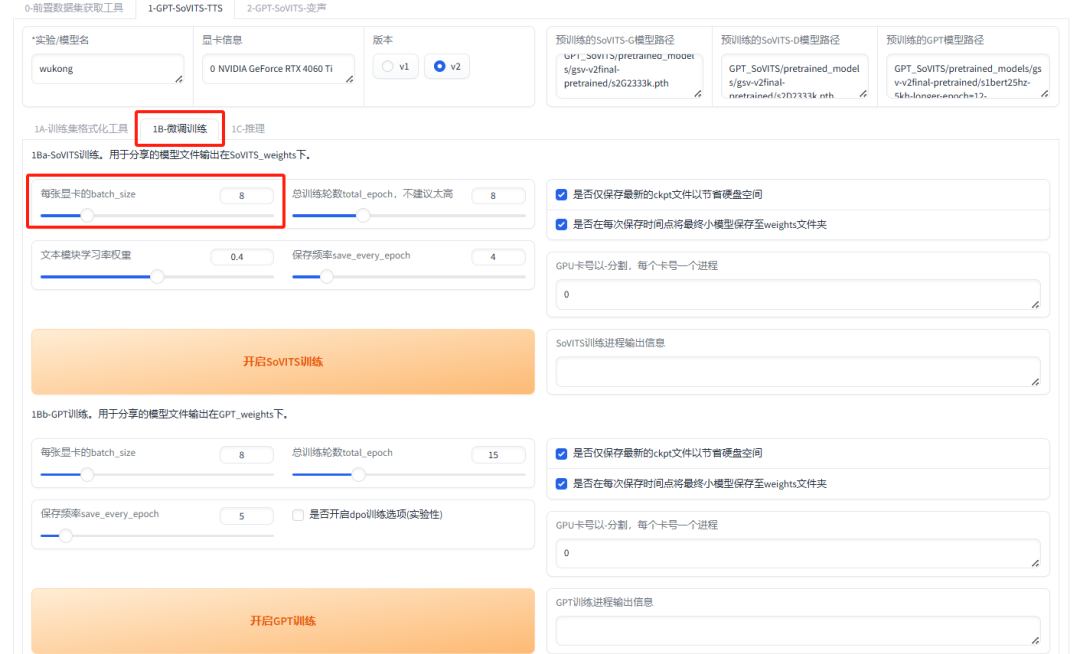
点击 “开始SoVITS训练” 和 “开始GPT训练”。
VITS 训练过程可能需要一些时间,请耐心等待,确保训练顺利完成。

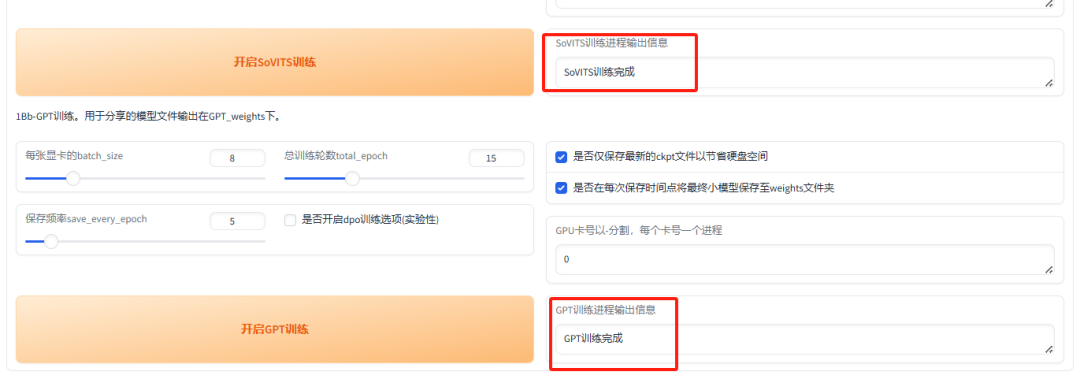
训练完成后,微调模型便已准备就绪,您可以进行后续的使用或部署操作。
3.推理:
点击 “1C-推理” 页签,进入推理界面。
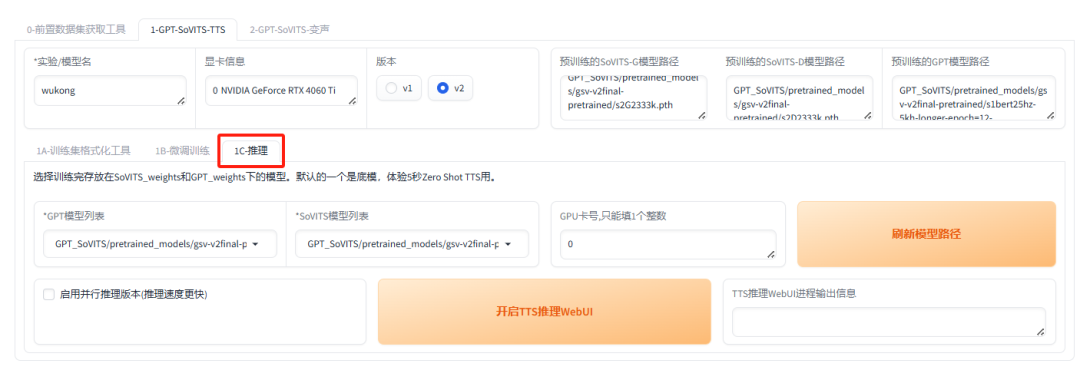
首先,点击“刷新模型路径”按钮,将刚刚训练完成的子模型加载进来,以便后续使用。
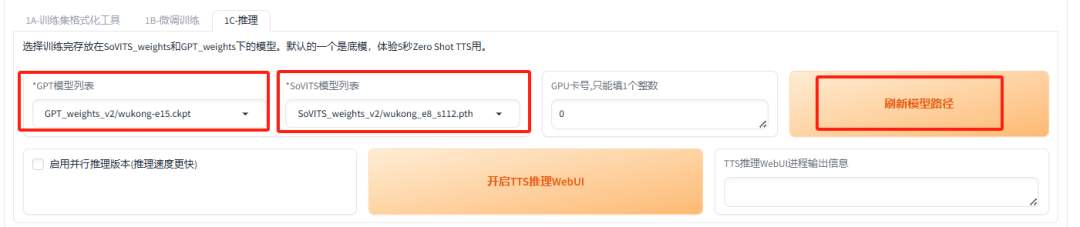
接下来,点击“开启TTS推理WebUI”按钮,即可启动推理过程,进行文本到语音的转换。
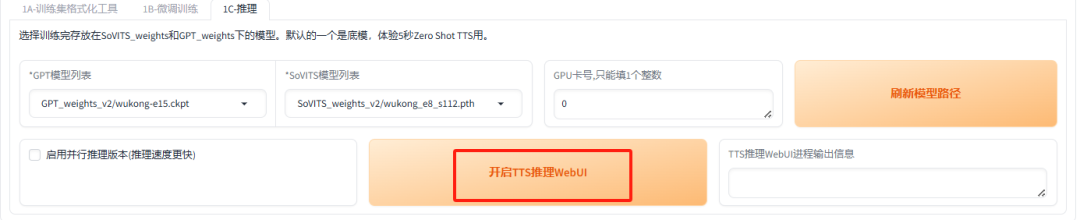
稍作等待,会弹出推理WebUI界面。
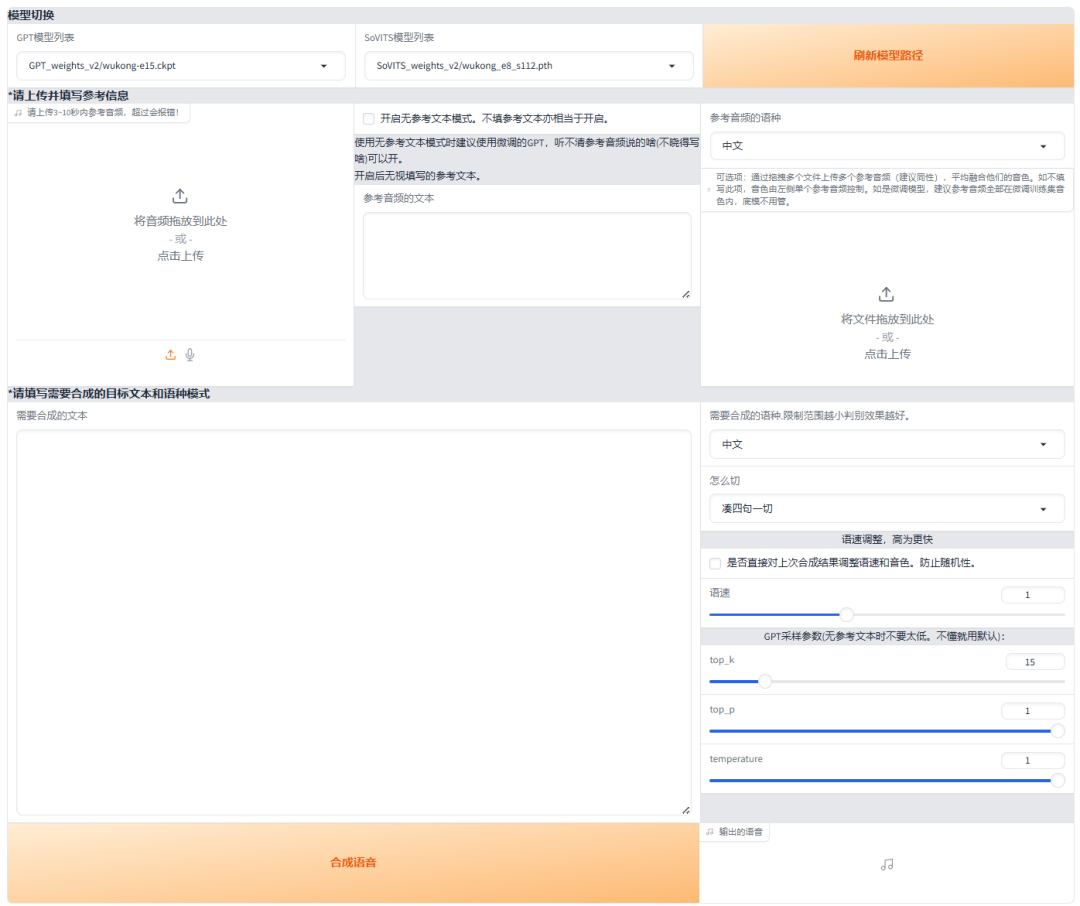
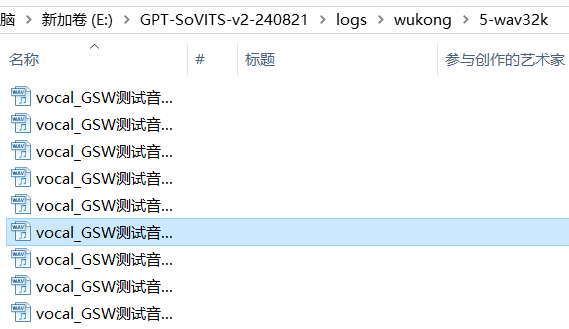
在进行推理之前,我们需要为模型提供一个目标音色的参考音频。您可以在 **\logs\wukong\5-wav32k** 路径下选择一个音频文件,作为参考音色进行推理。
要使用的文本文件可以在 **\logs\wukong** 路径下找到,您可以从该文件中提取文本内容进行推理操作。
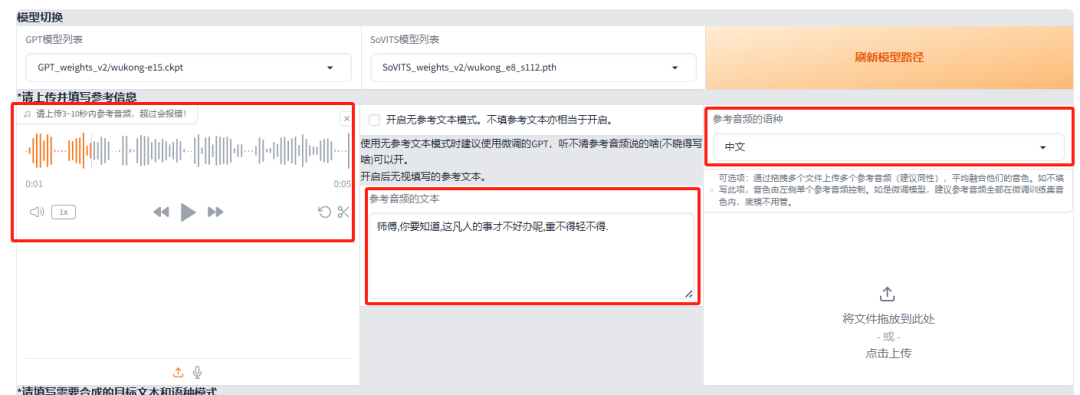
接下来,我们将参考音频文件、文本内容以及目标语音分别填入推理界面相应的位置,准备进行推理操作。
接下来,将您想要生成的文本填写到下方的输入框中,并选择一种自动切分方式,或者根据需要进行手动切分,以便更好地控制语音生成的节奏。
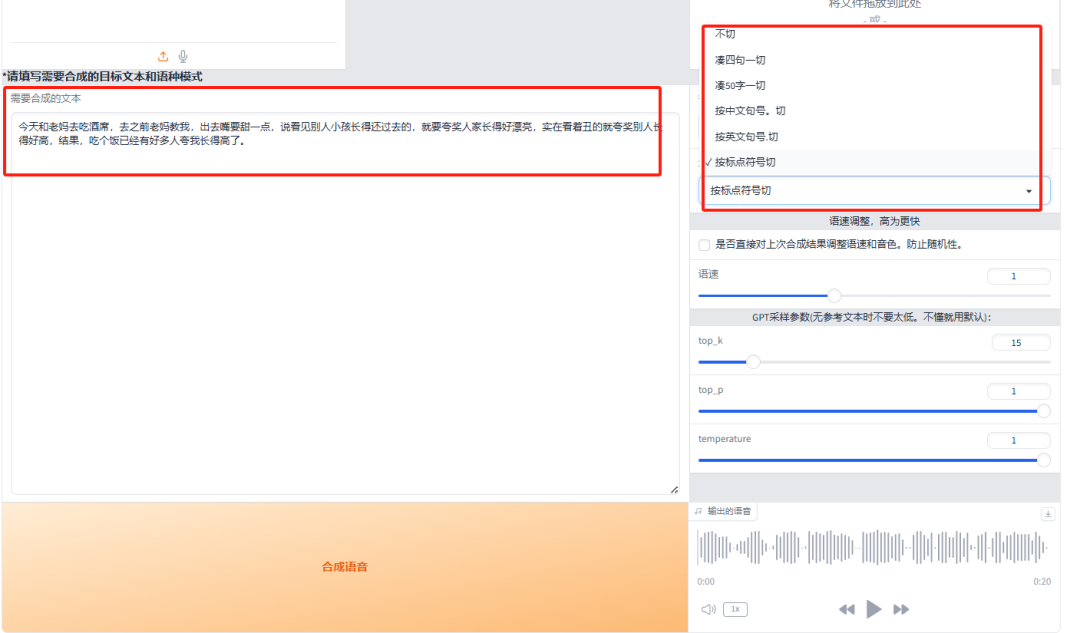
点击 “合成语音”。
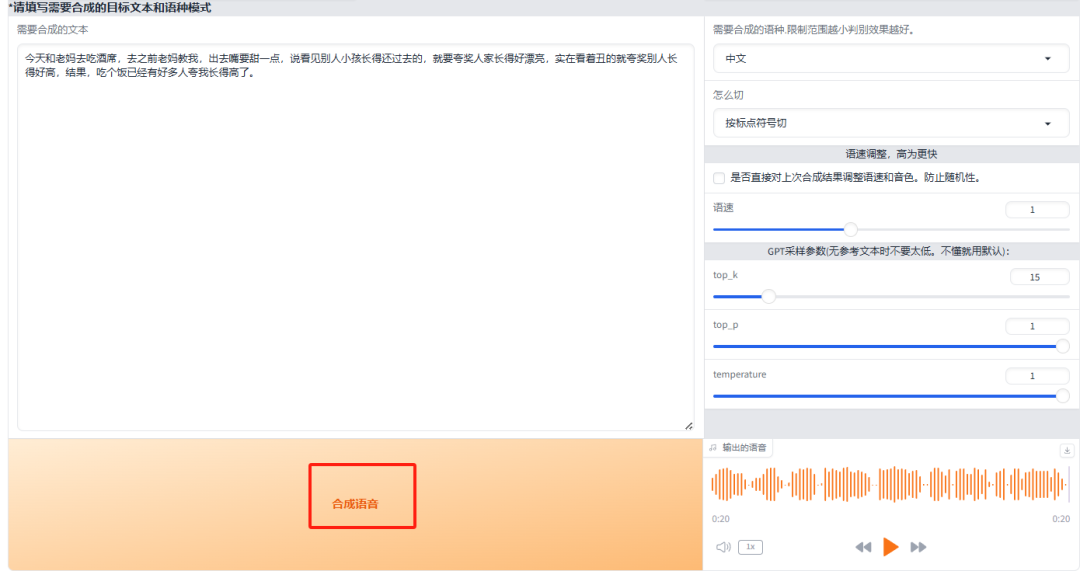
听一下效果:
至此,推理部分已经完成。
我们现在已经成功训练并获得了一个TTS模型。您可以在推理界面输入任何文本,模型将根据输入内容进行语音朗读。
总结
GPT-SoVITS-WebUI 凭借其卓越的功能和用户友好的界面,为语音技术的爱好者和开发者提供了一个强大的工具平台。它显著提升了语音合成、识别和处理的效率与便捷性。随着技术的持续进步,我们期待 GPT-SoVITS-WebUI 在未来能够为语音技术的创新和应用带来更多的机遇与可能性,推动这一领域的发展迈向新的高度。

